
Cavemen vs Philosophers
What Happens When You Tell an LLM How to Think, Not Just How Much

A few days ago I came across a repo called caveman by Julius Brussee. He got it right - this is brilliant.
The idea is simple: you put a system prompt that strips filler from LLM output. Drop articles, drop hedging, drop pleasantries. The model still reasons the same way, it just talks less. There’s a paper behind it (”Brevity Constraints Reverse Performance Hierarchies in Language Models,” March 2026) showing that forcing brevity can improve accuracy by 26 percentage points on some benchmarks. The compression is mouth, not brain.
I read it and thought: what if we went further? Caveman tells the model to shut up. What if instead we told it what kind of thinking to keep?
I forked the repo and spent an afternoon building philosopher modes.

The philosophers
Three modes, each encoding a different epistemological filter as a system prompt. The names come from the thinkers, the modes are the concepts:
Hard-to-vary mode (from David Deutsch). Every detail in the response must be load-bearing. If you can swap a noun and the sentence still works, the noun was decorative. Kill it. Name the mechanism, not the category. “It’s a race condition” gets deleted if you also wrote “X and Y both write to Z.” The mechanism IS the explanation.
Falsifiable mode (from Karl Popper). Every claim must come with its refutation test. No “might work,” no “best practices,” no “it depends.” Every diagnosis includes how to disprove it: “Conjecture: stale cache. Falsify: curl -H ‘Cache-Control: no-cache’. Same error? Not cache.” If you can’t state what would prove you wrong, don’t state it.
Antifragile mode (from Nassim Taleb). Via negativa applied to technical advice. Subtract before you add. Name the fragility before the feature. “Fragile: monolith deploys = all-or-nothing. Remove: coupling via shared DB.” Lead with what to stop doing. State the asymmetry. No “on the one hand, on the other hand.”
I ran all three against caveman and a normal baseline across 10 technical prompts, 5 models, 3 trials where budget allowed. Over 1000 tests total. Used the existing caveman benchmark (same prompts, same measurement: output token count, no quality scoring).
The first results looked like a breakthrough
On Sonnet 4.6, the philosophers dominated:
Antifragile: 62% average token savings. Falsifiable: 58%. Hard-to-vary: 53%. Caveman: 52%.
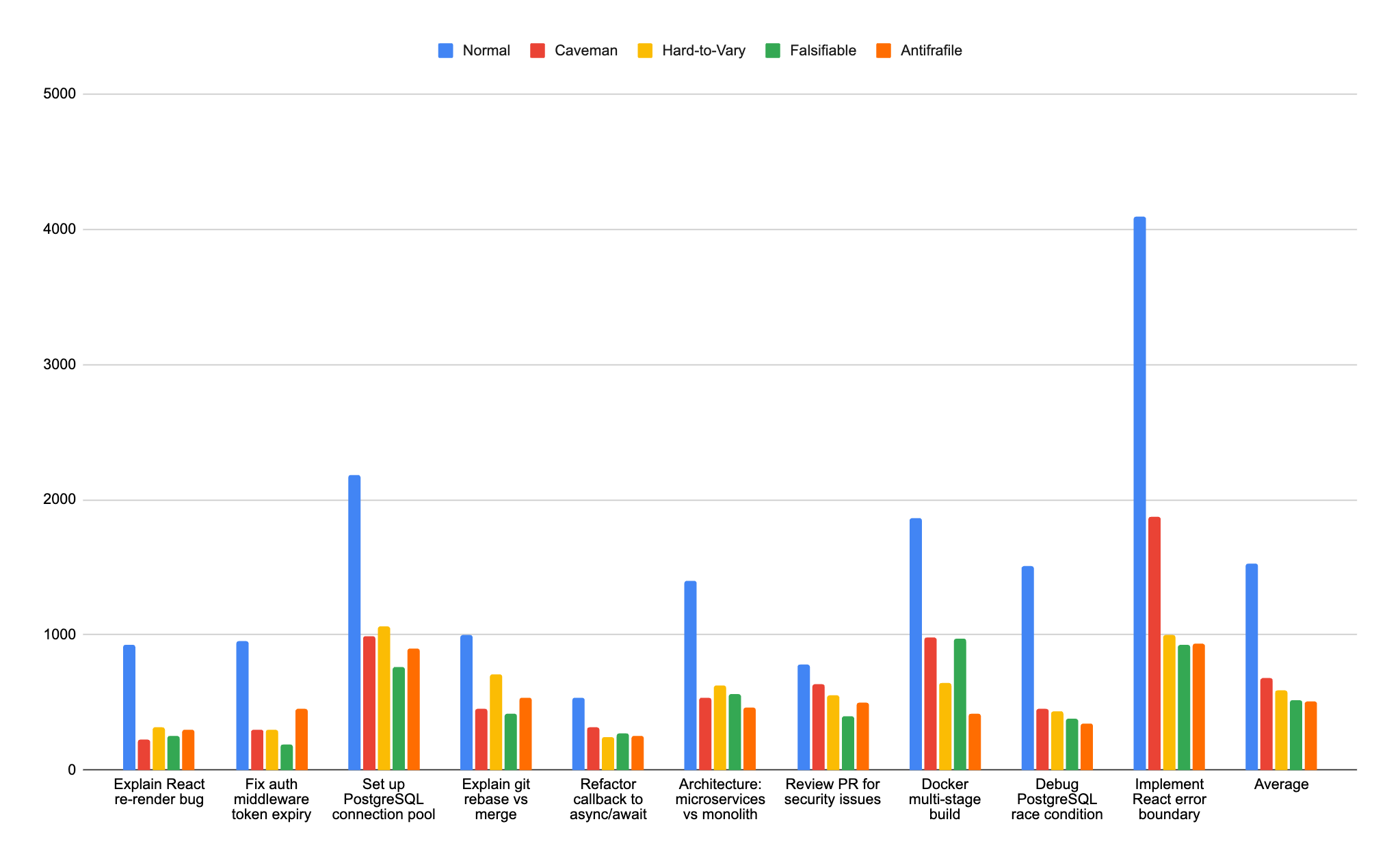
Antifragile hit 82% on some prompts. The “subtract first” framing maps cleanly to terse answers. Falsifiable’s conjecture/falsifier pattern compressed even on review tasks where the model would normally hedge for paragraphs. I wrote in my notes that caveman was “Pareto-dominated.”
I was wrong.
The philosophers got beaten. Hard.
Then I tested other models. And the picture inverted.
Opus 4.6: every mode lost ground. Hard-to-vary went negative on one prompt, producing 15% more tokens than baseline. The “name the mechanism, go one level deeper” rules added explanatory structure that cost more tokens than it saved. On a topic where the answer IS an explanation, the rigor budget ate the compression budget.
Haiku 4.5: the structural modes collapsed. Hard-to-vary averaged 10% savings. Five out of ten prompts went negative. The worst was -46%. Meanwhile caveman sat at 52%, identical to its Sonnet score.
gpt-5.4-mini: complete ranking inversion. Caveman won. Falsifiable collapsed to 18%.
gpt-5.4 (reasoning auto): three out of four modes produced more tokens than baseline on average. Antifragile went -87% on one prompt. Even caveman struggled.

Caveman: 31 points of variance across models. Hard-to-vary: 70. Falsifiable: 77.
But I saw something in the wreckage.
What the failures revealed
The philosopher modes have rules that add required content. “Name the mechanism.” “State the falsifier.” “Name the fragility.” These are positive injection rules. On Sonnet, the model is smart enough to compress while satisfying those rules. On smaller or differently-tuned models, it satisfies them by expanding.
Caveman has only deletion rules. Its worst case is no-op. It can never make things longer because every rule says “remove,” never “add.”
Subtraction is robust. Addition is fragile.
The making of the ultraphilosopher
The question became: can you keep the philosophical content but express every rule as a deletion?
Here’s the core reframing. Same filter, different expression:
Hard-to-vary (positive injection): “Name the mechanism, not the category”
Ultraphilosopher (deletion): “Delete category-level claims when a mechanism statement exists”
Falsifiable (positive injection): “Every recommendation includes failure condition”
Ultraphilosopher (deletion): “Delete claims you cannot state a falsifier for”
Antifragile (positive injection): “Expose hidden optionality”
Ultraphilosopher (deletion): “Delete recommendations that don’t acknowledge a tradeoff”
One set of rules can expand output. The other can only shrink it. The worst case for ultraphilosopher is “did nothing.” It literally cannot make things worse (last famous words).
I also built two companion modes on the same principle:
Imperatives restricts grammatical mood. Every non-code sentence must be a command. “The bug is caused by X” becomes “Fix X.” If a sentence can’t be rewritten as an imperative, delete it.
Anti-elaboration is a pattern blacklist. Delete intros (”I’ll help...”), delete transitions (”Furthermore...”), delete closings (”Hope this helps!”), delete restatements.
I committed to a falsifier before testing any of them: average savings on Haiku must exceed 30%, no prompt may go negative by more than 10%. If the mode fails this test, it doesn’t ship.
What the ultraphilosopher actually produces
The prompt: “Why is my React component re-rendering?”
Normal response (~822 tokens on Sonnet): multiple paragraphs explaining shallow comparison, object references, the React reconciliation algorithm, several possible causes, caveats, and a gentle suggestion to try useMemo.
Ultraphilosopher (~116 tokens, 86% saved):
Inline obj prop → new ref each render → shallow compare fails → re-render.
Wrap in `useMemo`. Falsify: useMemo deps wrong → still re-renders.
The mechanism is there (object literal creates new reference). The falsifier is there (wrong deps breaks the fix). The category-level filler (”this is a common React performance issue”) is gone because ultraphilosopher’s rule says: delete category-level claims when a mechanism is stated. The mechanism already told you it’s a performance issue. Saying so adds zero information.
“Should I use Redis?”:
Redis fits read-heavy + tolerates stale + dataset < memory.
Wrong if write-heavy + needs consistency: invalidation cost > DB cost.
Test: hit ratio week 1 — under 80% means wrong tool.
Three conditions, one failure case, one empirical test. No “there are several factors to consider.”
The results
All three new modes passed. None went negative on any prompt across any model tested.
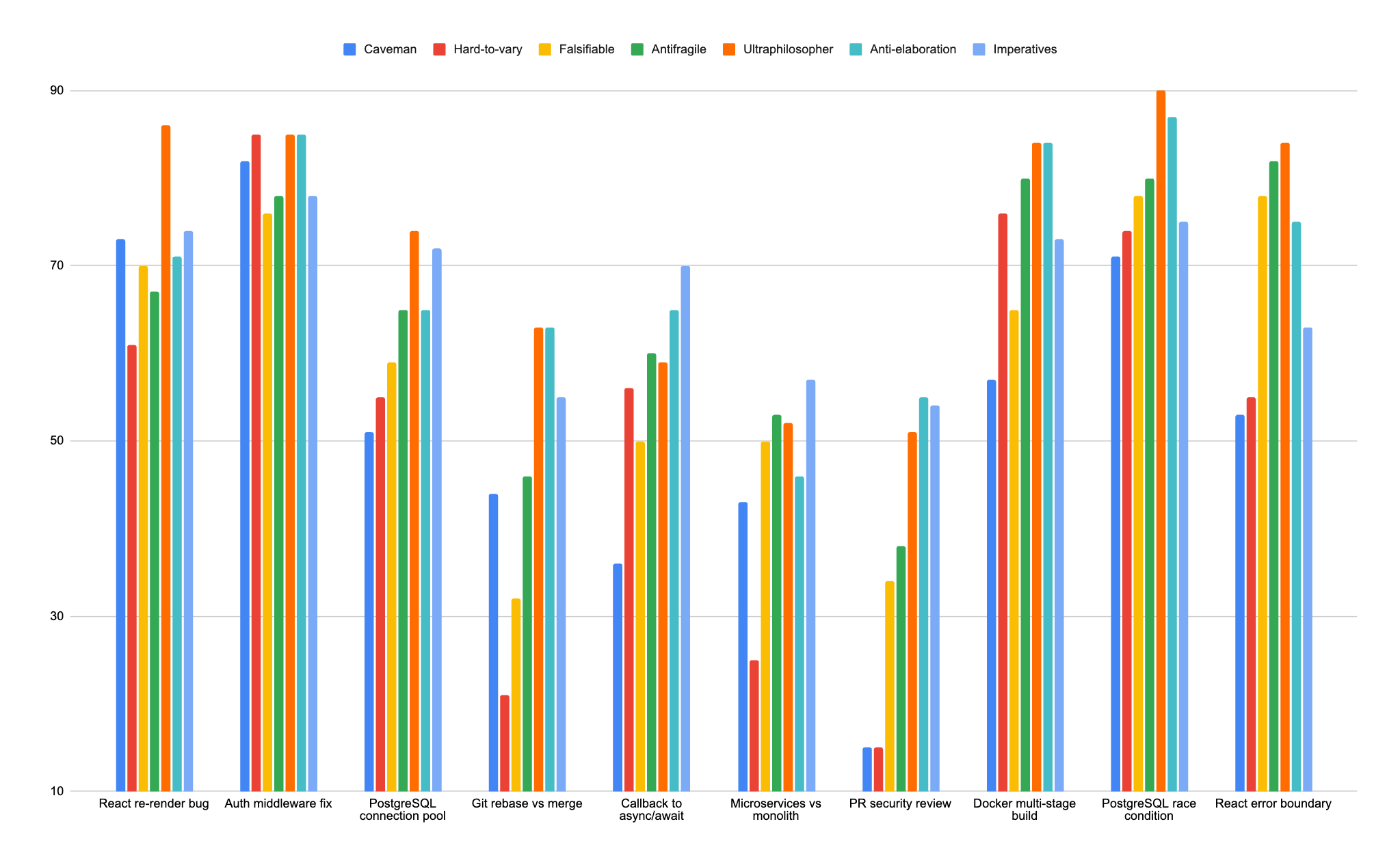
On Sonnet 4.6, ultraphilosopher hit 73% average savings. The previous champion (antifragile) had been 62%. On one prompt, ultraphilosopher saved 90% of tokens. Its worst result on Sonnet (51%) was still higher than caveman’s average.
On Haiku, where hard-to-vary had collapsed to 10% and gone negative on five prompts, ultraphilosopher delivered 58%. Same philosophical content, different rule expression. The deletion-only reframing moved Haiku compression from 10% to 58%.
On gpt-5.4-mini: ultraphilosopher 71%, imperatives 67%. Both beat round-1 caveman (48%) by over 20 points.

The megasaiyan experiment

I tried fusing all three winners into one mode. The conjecture: content subtraction, syntactic restriction, and ceremony deletion attack orthogonal axes. Combined, they should compound.
I committed the falsifier before testing: megasaiyan must beat the best single component by at least 5 points. If it doesn’t, the fusion hypothesis is falsified. Ship the components separately.
It didn’t. Megasaiyan averaged 67% on gpt-5.4-mini. Ultraphilosopher alone: 71%. On one prompt, imperatives scored 81% with pure command form while megasaiyan dropped to 43%. The philosophical filters reintroduced descriptive content that imperatives correctly deletes. The rules interfere.
Without a pre-committed criterion, I would have looked at 67% and called it competitive. With the criterion, the decision was automatic. Fusion falsified. Ship the components separately.
What this is and what it isn’t
What it isn’t. Serious research. Ten prompts, one domain (technical/coding), no objective quality measurement. A 60% token saving that produces a wrong answer is a regression, not a win. I used the existing caveman benchmark, not my own. No long sequences, no long context windows, no multi-turn conversations, no non-English prompts. I tested five models from two vendors. The sample would make a statistician cry.
What it is. An afternoon experiment that produced a testable design principle and one working mode that outperformed everything else on every model I tested.
What I notice using it. Responses feel visibly faster. When 70% of tokens disappear, the response arrives in a fraction of the time. For technical work, where I already know the domain and want the model to be precise rather than educational, the compressed answers feel better to me. That’s an anecdote, not data.
I’d be curious to learn the answers
Do shorter skill files survive better on smaller models? The input token cost per call might matter more than I assumed.
Does compressed output lose accuracy, or (as the original brevity paper suggests) does it sometimes improve it? A quality benchmark would answer whether the philosophers are actually smarter than the cavemen, or just quieter.
Does this generalize beyond coding prompts? Writing, analysis, research, creative work have different compression profiles. The principle (subtraction beats addition) should hold. The magnitude is an open question.
What survived falsification
After 1000+ tests across 5 models and 9 modes, three conjectures falsified:
“Bigger model = better compression.” Wrong. Opus and gpt-5.4 compressed worse than their smaller siblings. Not because they ignored the instructions, but because their reasoning overhead is structural. They may follow compression rules perfectly and still produce more tokens.
“Structural rules with positive injection scale across models.” Wrong. They work on Sonnet and collapse everywhere else.
“Fusion of orthogonal compression strategies compounds.” Wrong. The rules interfere.
Two confirmed:
Subtraction-only rules generalize across model sizes. And the relationship between model size and compression effectiveness is non-monotonic, with a sweet spot in the middle.
The design principle I’d carry forward to any system prompt work: if you can express a rule as a deletion, do it. The worst case is no-op. The moment you ask a model to add something, you’ve opened the door to unbounded expansion.
Why this matters
Output tokens are the expensive part of any API call. At the time of writing, Sonnet 4.6 charges $15 per million output tokens. Haiku 4.5 charges $5. Opus 4.6 charges $25.
Ultraphilosopher saves 73% of output tokens on Sonnet. That’s $10.95 per million tokens you don’t generate. On Haiku, 58% savings = $2.90 per million. On Opus, if the numbers hold, you’re looking at roughly $12-13 saved per million output tokens.
Scale that to a production workload generating 100M output tokens per month on Sonnet. Normal cost: $1,500. With ultraphilosopher: ~$405. That’s $1,095/month from a system prompt change. No infrastructure work, no model switch, no fine-tuning.
And the cost saving is arguably the less interesting part. The latency improvement is proportional to the token reduction. 73% fewer tokens means the response arrives in roughly a quarter of the time. For agentic workflows where one LLM call feeds into the next, that compounds across every step in the chain.
The results are here, benchmarks, raw JSONs, all skill files, including the ultraphilosopher. Shout out to Julius Brussee and the original caveman authors for building something worth forking.
More experiments coming.
Love this experiment. I’d be interested in running something like auto-researcher on this, to fine-tune and test more scenarios (prompts) and models.